🖥️ 들어가며
📌 Clustered Index
: 테이블의 물리적 순서를 결정하고, 테이블당 하나만 생성할 수 있습니다.
논리적으로 사번 / 이름 + 입사일자 / 연봉에 대한 각 Clustered Index를 만들 순 없습니다. [인덱스: 이름 + 입사일자]로 만드는 경우 실제 테이블의 데이터가 이 기준으로 정렬되기 때문입니다.
✏️ 1. Clustered Index와 IOT
- SQL Server: Clustered Index
- 일반적인 B-tree 구조, 키 값이 같은 레코드가 한 블록에 모이도록 저장하는 구조입니다.
- 한 블록에 모두 담을 수 없을 때는 새로운 블록을 할당해 클러스터 체인으로 연결합니다.
- 다중테이블 인덱스 클러스터
- 두 개 이상의 관련 테이블을 동일한 클러스터 키를 기반으로 같은 물리적 위치에 저장하는 구조입니다.
- 작동 방식
- 클러스터 키 컬럼(ex: DEPTNO)을 기준으로 여러 테이블의 관련 데이터 → 같은 데이터 블록에 저장
- 각 로우는 클러스터 키 ID를 가지고, 블록 헤더는 클러스터 키 ID와 키 정보를 포함
- 정규화로 분리된 테이블을 하나의 테이블처럼 액세스해야 할 때 유용합니다. (조인 연산 효율성이 높아짐)

- Oracle: IOT(Index Organized Table)
- 둘다 테이블 데이터를 인덱스 구조로 저장하는 유사한 개념입니다.
- 인덱스와 테이블 데이터가 동일한 순서로 정렬, 동일한 구조로 저장됩니다.
- Leaf Node: 인덱스 키 + 테이블 데이터 모두 포함합니다.
- 테이블 액세스가 불필요 → R.A 발생하지 않아 검색 속도가 빨라집니다.

- ⭐⭐⭐ IOT 특징
- 인덱스와 테이블 데이터가 동일한 순서로 정렬
- RowID 없음
- PK Key 값 사용
- RowID를 사용하지 않는 이유
- 페이지 개편
- 새로운 데이터가 기존 페이지에 삽입될 공간이 없으면 페이지 분할이 발생합니다.
- 페이지 개편 시 Index Split이 필요한데, 이 경우 데이터의 RowID 블록이 변경될 수 있습니다. (물리적 저장 위치 변경) - 휘발성 RowID
- RowID는 DBA와 로우 번호로 구성되어 있기 때문에 블록이 변경되면 RowID도 바뀌게 됩니다.
- 만약 [인덱스: 이름 + RowID]로 정렬되어 있는 경우, RowID가 변경되면 인덱스 정렬도 다시 구성해야 하므로 성능 저하가 발생할 수 있습니다.
=> 즉, 페이지 분할 시 데이터 이동으로 인한 RowID 변경을 방지하기 위해 Secondary Index로 PK Key 값을 사용합니다.
- 페이지 개편
- RowID를 사용하지 않는 이유
✏️ 2. Heap Table과 IOT 비교
- Heap Table은 전통적인 방식으로 데이터를 저장하고, IOT는 인덱스 구조로 데이터를 저장합니다.
| 구분 | Heap Table | IOT(Index Organized Table) |
| 인덱스를 이용한 테이블 Search | RowID (데이터 직접 접근) |
- (인덱스 구조 자체가 데이터를 포함) |
| PK 구조 | Key + RowID | Key |
| Secondary Key 구조 | Key + RowID | Key + PK |
| 테이블의 RowID 변화 | 비휘발성 | 휘발성 |
| 속도 | C.F 따라 상이 | PK 조회: 매우 높음 Secondary Index: 낮음* *Secondary Index에서 PK를 찾고 → IOT 테이블 검색하는 과정에서 PK를 통한 추가적인 수직적 스캔이 필요하기 때문 |
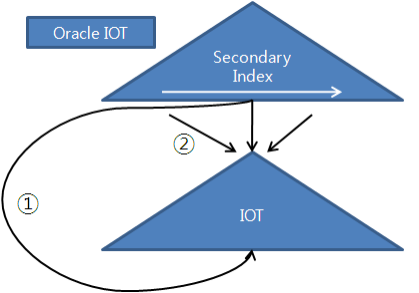
✏️ 3. IOT와 Clustered Index 활용
- IOT: Index Organized Index
- 크키가 작고 NL(Nested Loop) 조인으로 반복 룩업하는 테이블
- 적은 컬럼 수 + 많은 로우 수의 테이블
- 넓은 범위 검색
- 읽기와 쓰기 패턴이 다른 테이블
- 하지만 대량의 DML 작업(삽입, 수정, 삭제) 시 성능이 저하될 수 있습니다.
→ 데이터를 정렬 상태로 유지해야 해서 오버헤드 발생 가능성 높음
- Clustered Index
- 해당 키 값을 저장하는 첫 번째 데이터 블록만 가리킨다는 점은 일반적인 B-tree 구조와 상이
(B-tree는 데이터 블록 내 모든 데이터를 가리킴) - 클러스터 키 값은 항상 Unique, 데이터 정렬 상태 유지
- 키 값 : 테이블 레코드 = 1 : M 관계 (일반 인덱스는 1 : 1 관계)
- 넓은 범위 검색에 유리 (C.F 매우 좋음), 읽기 중심 작업
- 하지만 새로운 값이 자주 입력되거나, 수정이 자주 발생하는 경우엔 불리합니다.
→ 새로운 클러스터 할당해야 하고, 클러스터를 자주 이동 시켜야 하기 때문
- 해당 키 값을 저장하는 첫 번째 데이터 블록만 가리킨다는 점은 일반적인 B-tree 구조와 상이
- 공통 고려사항
- IOT와 Clustered Index 모두 읽기 중심 작업에 유리합니다.
- 데이터를 정렬된 상태로 유지합니다.
- 읽기 중심이라면? IOT 또는 Clustered 활용 고려
- 쓰기 중심이라면? 일반 테이블, 비클러스터형 인덱스가 적합
(데이터를 정렬 상태로 유지하지 않아 삽입/수정/삭제 작업이 빠름)
📒 정리하면
- Clustered Index(SQL Server), IOT(Index Organized Table, Oracle)는 테이블 데이터를 인덱스 구조로 저장해 데이터 접근 속도를 향상시키는 유사한 개념입니다.
- 둘 다 테이블당 하나만 생성 가능하며, 테이블의 물리적 순서를 결정합니다.
- IOT: RowID 대신 PK Key 값을 사용해 페이지 분할 시 데이터 이동으로 인한 RowID 변경 문제를 해결합니다.
- Heap Table: 전통적인 데이터 저장 방식을 사용하고, IOT: 인덱스 구조로 데이터를 저장해 PK 조회 성능이 우수합니다.
- IOT, Clustered Index: 읽기 중심 작업, 넓은 범위 검색에 유리하지만, 빈번한 데이터 변경 시 성능이 저하될 수 있습니다.
(+ PK가 아닌 다른 컬럼으로 대량 조회 시 오히려 성능이 저하될 수 있음)
반응형



