[SQL튜닝/인덱스와 조인] 고급 조인 테크닉2 (누적 매출 구하기, 선분이력 끊기, 데이터 복제를 통한 소계 구하기, 상호배타적 관계의 조인, 최종 출력건에 대해서만 조인, 선분 이력 조인, 점이력 조회)
🖥️ 들어가며
📌누선최데복 점선징아
누적 매출 구하기
선분이력 끊기
최종 출력건에 대해서만 조인
데이터 복제를 통한 소계 구하기
점이력 조회
선분 이력 조인
징검다리 조인
아크 관계의 조인(상호배타적 관계)
✏️ 1. 누적 매출 구하기
👉🏻 고급 조인 테크닉1: 누적 매출 구하기 내용 보러가기
✏️ 2. 선분 이력 끊기
- ⭐⭐⭐ 시작일자~종료일자를 고려하여 필요한 선분만 끊어서 가져오면 됩니다.

- 월말을 기준으로 선분을 끊는 경우
- SELECT
GREATEST (시작일자, '20240101') AS 시작일자,
LEAST (종료일자, '20240131') AS 종료일자 - WHERE 시작일자 <= '20240131'
AND 종료일자 >= '20240101';
- SELECT
-- 8월 기간동안 특정고객에 대한 할인율 정보 쿼리문
SELECT 고객번호
, GREATEST (시작일자, '20190801') AS 시작일자
, LEAST (종료일자, '20190831') AS 종료일자
, 할인율
FROM 고객별_할인율
WHERE 고객번호 = 'C101'
AND 시작일자 <= '20190831'
AND 종료일자 >= '20190801';
-- 조인 케이스 (B 테이블이 기준역할)
SELECT 고객번호
, GREATEST (A.시작일자, B.시작일자) AS 시작일자
, LEAST (A.종료일자, B.종료일자) AS 종료일자
, 할인율
FROM 고객별_할인율 A, 월도 B
WHERE A.고객번호 = 'C101'
AND B.고객번호 = A.고객번호
AND A.시작일자 <= B.종료일자
AND A.종료일자 >= B.시작일자;
✏️ 3. 데이터 복제를 통한 소계 구하기
- ⭐⭐⭐ 연결고리 없이 조인하면 결과가 카테시안 곱으로 나옵니다.
- ⭐⭐⭐ 아래 쿼리문은 괄호 넣기 문제로 나올 수 있습니다.
GROUP BY DEPTNO, NO, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계')
ORDER BY 1, 2
-- 소계 구하기
-- 기본 테이블
SELECT B.NO,
A.DEPTNO,
A.EMPTNO,
A.SAL
FROM EMP A,
(SELECT ROWNUM NO FROM DUAL
CONNECT BY LEVEL <= 2
) B;
-- 기본 -> 전통적인 방식
SELECT A.DEPTNO 부서,
DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계') 사번,
SUM(SAL) 급여합,
ROUND(AVG(SAL)) 급여평균
FROM EMP A,
(SELECT ROWNUM NO FROM DUAL
CONNECT BY LEVEL <= 2
) B
GROUP BY DEPTNO, NO, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계')
ORDER BY 1, 2;
-- 기본 -> ROLL UP 함수를 이용한 방식
SELECT DEPTNO
, CASE WHEN GROUPING (EMPNO) = 1 AND GROUPING (DEPTNO) = 1 THEN '총계'
WHEN GROUPING (EMPNO) = 1 THEN '부서계'
ELSE TO_CHAR(EMPTNO)
END 사원번호
, SUM(SAL) 급여합
, ROUND(AVG(SAL)) 급여평균
FROM EMP
GROUP BY ROLLUP(DEPTNO, EMPNO)
ORDER BY DEPTNO, 사원번호;- 전통적인 방식 쿼리문 설명
- DECODE: NO가 1일 때 EMPNO를 문자열로 변환하여 반환 / NO가 2일 때 부서계 문자열을 반환합니다.
- ROLLUP 함수 방식 쿼리문 설명
- CASE WHEN GROUPING (EMPNO) = 1
- 0: 원천데이터 / 1: 소계 - GROUP BY ROLLUP(DEPTNO, EMPNO): 부서와 사원번호별로 그룹화 → 중간소계(부서별), 전체총계를 생성합니다.
- 만약 GROUP BY DEPTNO, ROLLUP(EMPNO) 였다면? 총계 행이 제거되었을 것입니다. (각 부서별 소계만 생성)
- CASE WHEN GROUPING (EMPNO) = 1
-- 기본 테이블
NO DEPTNO EMPTNO SAL
1 10 7782 2450
1 10 7839 2850
1 20 7369 800
2 10 7782 2450
2 10 7839 2850
2 20 7369 800
... (모든 사원에 대해 NO 1, 2로 반복)
-- 전통적인 방식 (소계 포함)
부서 사번 급여합 급여평균
10 7782 2450 2450
10 7839 2850 2850
10 부서계 5300 2650
20 7369 800 800
20 7566 2975 2975
20 부서계 3775 1887
... (각 부서별 개별 사원 + 부서 소계)
-- ROLLUP 방식 (소계, 총계 포함)
부서 사원번호 급여합 급여평균
10 7782 2450 2450
10 7839 2850 2850
10 부서계 5300 2650
20 7369 800 800
20 7566 2975 2975
20 부서계 3775 1887
...
총계 xxxxx yyyy
- GROUPING SET 함수
- 일별, 월별 집계를 동시에 수행하고자 하는 경우, Grouping Set 함수를 쓸 수 있습니다.
- 이는 UNION ALL을 사용한 두 개의 별도 쿼리를 대체합니다.
- ⭐⭐⭐ GROUP BY GROUPING SETS (
(TO_CHAR(ORDER_DT, 'yyyymmdd'), CUST_NO), -- 일별
(TO_CHAR(ORDER,DT, 'yyyymm'), CUST_NO)) -- 월별 - ⭐⭐⭐ ORDER BY DECODE(구분, '일별', 1, 2), ...
-- UNION ALL을 사용하는 방식
SELECT '일별',
SUBSTR(ORDER_DT, 1, 8), -- 일별
CUST_NO,
SUM(ORDER_PRICE)
FROM T_ORDER74
WHERE ORDER_DT >= '20100601'
AND ORDER_DT < '20100701'
GROUP BY SUBSTR(ORDER_DT, 1, 8);
UNION ALL -- 월별, 일별 집계 합집합
SELECT '월별',
SUBSTR(ORDER_DT, 1, 6), -- 월별
CUST_NO,
SUM(ORDER_PRICE)
FROM T_ORDER74
WHERE ORDER_DT >= '20100601'
AND ORDER_DT < '20100701'
GROUP BY SUBSTR(ORDER_DT, 1, 6);
-- GROUPING SET 함수를 사용한 방식
SELECT 구분,
DECODE(ORDER_NM, NULL, ORDER_DT, ORDER_MM) 일자,
CUST_NO, ORDER_PRICE_SUM
FROM
(SELECT DECODE(TO_CHAR(ORDER_DT, 'yyyymm'), NULL, '일별', '월별') 구분,
TO_CHAR(ORDER_DT, 'yyyymmdd') ORDER_DT,
TO_CHAR(ORDER_DT, 'yyyymm') ORDER_MM,
CUST_NO,
SUM(ORDER_PRICE) ORDER_PRICE_SUM
FROM T_ORDER74
WHERE ORDER_DT BETWEEN TO_DATE('20100601', 'yyyymmdd')
AND TO_DATE('20100630 235959', 'yyyymmdd hh24miss')
GROUP BY GROUPING SETS(
(TO_CHAR(ORDER_DT, 'yyyymmdd'), CUST_NO), -- 일별
(TO_CHAR(ORDER_DT, 'yyyymm'), CUST_NO)) -- 월별
) X
ORDER BY DECODE(구분, '일별', 1, 2), ORDER_DT, ORDER_NM, CUST_NO;-- 결과 테이블
구분 일자 CUST_NO ORDER_PRICE_SUM
일별 20100601 1001 50000
일별 20100601 1002 30000
일별 20100602 1003 40000
...
월별 202006 1001 500000
월별 202006 1002 600000
월별 202006 1003 550000
...
✏️ 4. 상호배타적 관계의 조인 (아크)
- 아크일 때 물리 모델은 다음과 같이 2가지 상황이 있을 수 있습니다.
- ⭐⭐⭐ 외래키 분리 방법
- 컬럼: 온라인권번호, 실권번호 두 컬럼을 따로 두고
- 입력: 레코드별로 둘 중 하나의 컬럼에만 값을 입력합니다.
(실권번호가 있다면 온라인권번호가 NULL, 온라인권번호가 있다면 실권번호가 NULL
⚠️ 이런 관계에서 INNER JOIN시 결과는 無 => 따라서 배타적 관계의 조인 방법은 일반적인 JOIN과 다릅니다.)
- ⭐⭐⭐ 외래키 통합 방법
- 컬럼: 상품권구분, 상품권번호 컬럼을 두고
- 입력: 상품권 구분이 '1' → 온라인권번호, 구분이 '2' → 실권번호를 입력합니다.
- ⭐⭐⭐ 외래키 분리 방법

- 외래키 분리 방법 - 쿼리문
- 컬럼: 온라인권번호, 실권번호 두 컬럼을 따로 두고
- 입력: 레코드별로 둘 중 하나의 컬럼에만 값을 입력하는 경우
- OUTER JOIN의 특징: 조인 실패시에도 결과가 나옵니다. (INNER JOIN은 실패 시 결과 출력 X)
- NULL은 조인을 시도하지 않습니다. (무조건 실패하기 때문에 즉, NULL과 다른 값을 비교하면 항상 false로 간주되기 때문에 NULL을 가지고 수직적 탐색을 하지 않음)
- ⭐⭐⭐ AND B.온라인권번호 (+) = A.온라인권번호
AND C.실권번호 (+) = A.실권번호;
SELECT A.주문번호, A.결제일자, A.결제금액,
NVL(A.온라인권번호, A.실권번호) 상품권번호,
NVL(B.발행일시, C.발행일시) 발행일시
FROM 상품권결제 A, 온라인권 B, 실권 C
WHERE A.결제일자 BETWEEN :DATE1 AND :DATE2
AND B.온라인권번호 (+) = A.온라인권번호 -- 기준 테이블: A (RIGHT OUTER JOIN)
AND C.실권번호 (+) = A.실권번호; -- 기준 테이블: A (RIGHT OUTER JOIN)
- 외래키 통합 방법 - 쿼리문
- 컬럼: 상품권구분, 상품권번호 컬럼을 두고
- 입력: 상품권 구분이 '1' → 온라인권번호, 구분이 '2' → 실권번호를 입력하는 경우
- 인덱스 Case 1: 결제일자 + 상품권구분
- ⭐⭐⭐ OUTER JOIN, DECODE 함수를 활용해 NULL인 경우 조인X → 비효율을 감소 시킵니다.
AND B. 온라인권번호 (+) = DECODE(A.상품권구분, '1', A.상품권번호)
AND C.실권번호 (+) = DECODE(A.상품권구분, '2', A.상품권번호)
- ⭐⭐⭐ OUTER JOIN, DECODE 함수를 활용해 NULL인 경우 조인X → 비효율을 감소 시킵니다.
-- 기존 쿼리문
SELECT A.주문일자, A.결제일자, A.결제금액, A.상품권번호,
NVL(B.발행일시, C.발행일시) 발행일시,
FROM 상품권결제 A, 온라인권 B, 실권 C
WHERE A.결제일자 BETWEEN :DATE1 AND :DATE2 -- => 총 10만건의 비효율 발생
AND B.온라인권번호 (+) = A.상품권번호 -- 1. 10만건 탐색 후 5만건 출력
AND C.실권번호 (+) = A.상품권번호; -- 2. 10만건 탐색 후 5만건 출력
-- 인덱스: 결제일자 + 상품권구분 => 튜닝한 쿼리문
SELECT A.주문일자, A.결제일자, A.결제금액, A.상품권번호,
NVL(B.발행일시, C.발행일시) 발행일시,
FROM 상품권결제 A, 온라인권 B, 실권 C
WHERE A.결제일자 BETWEEN :DATE1 AND :DATE2
AND B.온라인권번호 (+) = DECODE(A.상품권구분, '1', A.상품권번호) -- 1이 아니면 NULL이므로 조인X
AND C.실권번호 (+) = DECODE(A.상품권구분, '2', A.상품권번호); -- 2가 아니면 NULL이므로 조인X- 인덱스 Case 2: 상품권구분 + 결제일자
- ⭐⭐⭐ 상품권구분이 드라이빙이 될 수 있도록 합니다.
WHERE A.상품권구분 = '1'
WHERE A.상품권구분 = '2' - UNION ALL을 사용하여 두 개의 SELECT문을 결합한 아래 쿼리문은 IN LIST ITERATOR와 유사한 효과를 냅니다.
(IN LIST ITERATOR: 여러 값을 하나씩 처리하는 방식, 여기서는 상품권구분 '1'과 '2'를 각각 처리) - 복합 인덱스의 최적화 전략: C1 + C2 + C3가 있을 때 최적화 전략은 다음과 같습니다.
- C1 등호(=) 조건, C2 BETWEEN 조건일 때, C2의 변별력에 따라 최적화 방법이 달라집니다.
- 변별력이 좋다면 BETWEEN 유지 / 좋지 않다면 IN 조건으로 변경하여 IN LIST ITERATOR를 사용하는 것이 효율적일 수 있습니다.
- 아래 쿼리의 복합인덱스 분석: 상품권구분 + 결제일자
- 변별력 문제
- 상품권구분: 변별력이 높습니다. (1 or 2)
- 결제일자: BETWEEN 조건으로 사용되며, 일반적으로 날짜 범위가 넓을 경우 변별력이 낮습니다.
- 최적화 전략
- 상품권구분을 드라이빙 조건으로 사용해야 합니다. (WHERE A.상품권구분 = '1' 또는 '2')
- 결제일자의 변별력이 낮더라도, 이미 상품권구분으로 데이터를 좁혀놨기 때문에 큰 영향을 미치지 않습니다.
따라서 결제일자의 BETWEEN 조건은 유지합니다.
- UNION ALL 사용
- 두 개의 SELECT문을 UNION ALL로 결합 => 각 상품권구분(1 or 2)에 대해 별도 쿼리를 실행합니다.
- 이는 IN LIST ITERATOR와 유사한 효과를 냅니다. 즉, 상품권구분 '1'과 '2'를 각각 처리할 수 있습니다.
- 최종 효과
- 각 상품권구분에 대해 인덱스를 효율적으로 사용할 수 있습니다.
- 결제일자의 변별력이 낮더라도, 상품권구분으로 먼저 데이터를 필터링하기 때문에 성능에 큰 영향을 미치지 않습니다.
- 변별력 문제
- ⭐⭐⭐ 상품권구분이 드라이빙이 될 수 있도록 합니다.
-- 인덱스: 상품권구분 + 결제일자 => 튜닝한 쿼리문
SELECT A.주문일자, A.결제일자, A.결제금액, A.상품권번호,
B.발행일시,
FROM 상품권결제 A, 온라인권 B
WHERE A.상품권구분 = '1'
AND A.결제일자 BETWEEN :DATE1 AND :DATE2
AND B.온라인권번호 = A.상품권번호;
UNION ALL
SELECT A.주문일자, A.결제일자, A.결제금액, A.상품권번호,
C.발행일시,
FROM 상품권결제 A, 실권 C
WHERE A.상품권구분 = '2'
AND A.결제일자 BETWEEN :DATE1 AND :DATE2
AND C.실권번호 = A.상품권번호;
✏️ 5. 최종 출력 건에 대해서만 조인하기
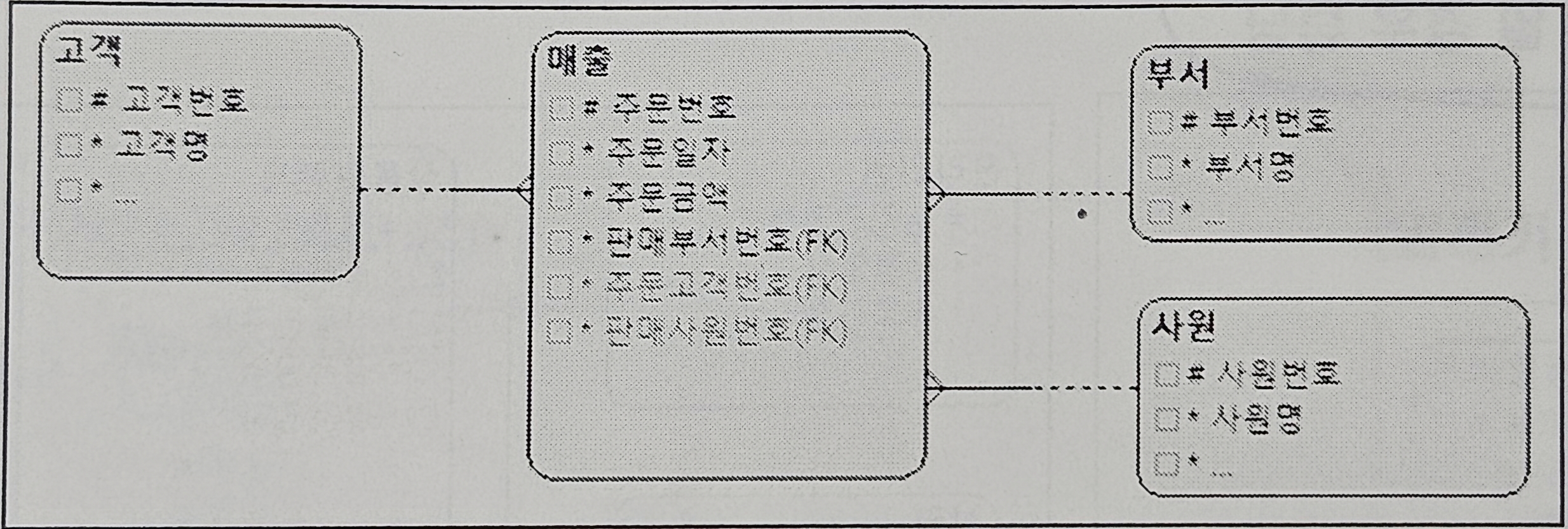
- 기본 정보
- 매출건수: 100만 건
- 특정부서의 매출건수: 1만건
- 4개의 테이블 조인
- 정렬: 판매부서번호, 주문일자, 판매사원번호
- 인덱스: 판매부서번호 + 주문일자
- 일반적인 게시판 출력 조인 방식
- 쿼리블록의 개수: 쿼리블록이 항상 3개입니다.
- ①: 1만건을 조회한다면 → ②: WHERE절*에 따라 41건을 조회하고 → ③: WHERE절**에 따라 10건을 조회합니다.
=> 따라서 ③번에서 JOIN되어야 합니다.
* WHERE ROWNUM <= 41
** WHERE NO BETWEEN 31 AND 40 - 정렬: 판매부서번호, 주문일자, 판매사원번호
인덱스: 판매부서번호 + 주문일자
=> 따라서 판매사원번호는 정렬이 필요합니다. 테이블 R.A를 해야 합니다.
- 판매사원번호로 정렬하기 위해서는 테이블에서 이 정보를 가져와야 합니다.
- 따라서 각 레코드에 대해 테이블 랜덤 액세스를 통해 판매사원번호를 가져와야 합니다. - ⚠️주의사항 ROWNUM vs. ROW_NUM
- WHERE ROWNUM <= 41; 41건만 조회하고 멈추지만
- WHERE ROW_NUM <= 41; 즉 ROW_NUM이라는 의사컬럼(Pseudo-column)을 만들면 1만 건을 전부 다 조회합니다.
- ⭐⭐⭐ ②번에서 ROWNUM <= 41까지 조회하는 이유: 안정적인 페이징 처리를 위함
② WHERE ROWNUM <= 41
③ WHERE NO BETWEEN 30 AND 40
SELECT NO, 주문번호, 주문일자, 주문금액, 주문고객명, -- (3)
판매부서명, 판매사원명
FROM (SELECT ROWNUM NO, 주문번호, 주문일자, 주문금액, 주문고객명, -- (2)
판매부서명, 판매사원명
FROM (SELECT O.주문번호, O.주문일자, O.주문금액, -- (1)
C.고객명 주문고객명,
D.부서명 판매부서명,
E.사원명 판매사원명
FROM 주문 O, 고객 C, 사원 E, 부서 D
WHERE O.판매부서번호 = 'D004'
AND C.고객번호 = O.주문고객번호
AND E.사원번호 = O.판매사원번호
AND D.부서번호 = O.판매부서번호
ORDER BY O.주문일자, O.판매사원번호
)
WHERE ROWNUM <= 41
)
WHERE NO BETWEEN 31 AND 40
ORDER BY NO;
- 즉, 일반적인 게시판 출력 조인 방식은
- (1) 1만건을 읽어서 → (2) JOIN 하고 → (3) SORT 과정에서 STOPKEY가 작동합니다.

- 인덱스 추가로 튜닝하기
- (1) 41건을 읽으면서 STOPKEY가 작동하고 → (2) 조인합니다.
- 기존 인덱스: 판매부서번호 + 주문일자
변경 인덱스: 판매부서번호 + 주문일자 + 판매사원번호 - 인덱스에 '판매사원번호'를 추가하면 테이블 R.A를 할 필요가 없습니다.
- ROWID로 조인하면 인덱스 없이도 테이블의 특정 행을 즉시 찾아갈 수 있습니다.
- ROWID: 오브젝트번호 + 파일번호 + 블록번호 + 로우번호
ROWID는 테이블의 특정 행을 직접 가리키는 포인터와 같습니다.
(👉🏻 ROWID 상세 내용 보러가기)
- ROWID: 오브젝트번호 + 파일번호 + 블록번호 + 로우번호
-- 아래의 2개 쿼리문의 일량은 동일
-- (1)
SELECT 주문번호, 주문고객번호, 판매사원번호, 판매부서번호, 주문금액
FROM (SELECT ROWID R_ID,
FROM 주문 N
WHERE 판매부서번호 = 'D004'
) X, 주문 O
WHERE O.ROWID = X.R_ID; -- ROWID로 조인하면 인덱스 없이도 찾아갈 수 있음
-- (2)
SELECT 주문번호, 주문고객번호, 판매사원번호, 판매부서번호, 주문금액
FROM 주문
WHERE 판매부서번호 = 'D004';
- 인덱스 추가 튜닝 - 쿼리문
- ①
- 인덱스(판매부서번호 + 주문일자 + 판매사원번호)를 고려하여 판매부서번호 = 'D004'인 데이터 조회
- 주문일자, 판매사원번호로 정렬
- 각 행의 ROWID와 ROWNUM 부여 - ②
- ROWNUM <= 41 조건으로 첫 41개 행만 선택
- ROWID와 NO만 보관 - ③
- 페이징: 31~40번째 행만 선택
- ROWID로 주문 테이블(O)과 조인*
- 고객(C), 사원(E), 부서(D) 테이블과 추가 조인 - ROWID를 통한 접근
- 테이블 R.A 횟수: 0번
O.ROWID = X.R_ID
: ROWID로 주문 테이블에 직접 접근하기 때문에 랜덤 액세스가 없습니다. - 테이블 R.A 횟수: 10번
X.NO BETWEEN 31 AND 40
: 위 조건으로 10개 행을 선택하고, 이 10개 행에 대해 각 테이블 조인 시 랜덤 액세스가 발생합니다.
- C.고객번호 = O.주문고객번호
- E.사원번호 = O.판매사원번호
- D.부서번호 = O.판매부서번호 - ⚠️ 만약 조인을 실패한다면?
: O.ROWID = X.R_ID에서 조인을 실패한다면, 메인 쿼리 실행 시점에서 데이터 정합성을 검증할 필요가 있습니다.
- 테이블 R.A 횟수: 0번
- ①
📌 O.ROWID = X.R_ID 조건 관련하여
1. ROWNUM vs. ROWID
- ROWNUM: 쿼리 결과에서 동적으로 할당되는 순번
- ROWID: 테이블의 각 행이 가지는 고유한 물리적 주소값
2. O.ROWID = X.R_ID
- 이미 ①번 서브쿼리에서 ROWID를 미리 추출했기 때문에, 전체 데이터를 스캔하지 않고 해당 ROWID로 직접 접근 가능
- 따라서 ROW_NUM(의사컬럼)과 같은 전체 스캔 문제가 발생하지 않음
-- 인덱스: 판매부서번호 + 주문일자 + 판매사원번호
SELECT NO, O.주문번호, O.주문일자, O.주문금액, -- (3)
C.고객명 주문고객명,
D.부서명 판매부서명,
E.사원명 판매사원명
FROM (SELECT R_ID, NO -- (2)
FROM (SELECT ROWID R_ID, ROWNUM NO -- (1)
FROM 주문
WHERE 판매부서번호 = 'D004'
ORDER BY 주문일자, 판매사원번호)
WHERE ROWNUM <= 41
) X, 주문 O, 고객 C, 사원 E, 부서 D
WHERE X.NO BETWEEN 31 AND 40
AND O.ROWID = X.R_ID
AND C.고객번호 = O.주문고객번호
AND E.사원번호 = O.판매사원번호
AND D.부서번호 = O.판매부서번호
ORDER BY NO;
✏️ 6. 징검다리 테이블 조인을 이용한 튜닝
✏️ 7. 선분 이력 조인
-- 고객(c) 테이블
고객번호 | 고객명 | 최종변경일자
123 | 홍길동 | 20150812
-- 고객등급이력(h) 테이블
고객번호 | 시작일자 | 종료일자 | 고객등급
123 | 20150101 | 20150630 | c
123 | 20150701 | 20150811 | b
123 | 20150812 | 99991231 | a
-- 최종이력 쿼리문의 결과: 123 홍길동 a
-- 직전선분 쿼리문의 결과: 123 홍길동 b- 개념
- 시작일자와 종료일자로 구성된 기간 데이터를 조인하는 기법입니다.
- 선분이력 조인 Case 1: 최종이력 구하기
- ⭐⭐⭐ 상수 - 연산자 - 컬럼 구조
- 상수 BETWEEN 시작일자 AND 종료일자
- :DT : 바인드 변수 = 쿼리 실행 시점에 하나의 고정된 값으로 결정됨 => 실행 중 값이 변하지 않음
- C.최종변경일자 : 고객테이블(C)의 특정 행(WHERE C.고객번호 = 123)이 결정되면 그 값도 하나로 고정됨
SELECT c.고객번호, c.고객명, h.고객등급
FROM 고객 c, 고객등급이력 h
WHERE c.고객번호 = 123
AND h.고객번호 = c.고객번호
AND :DT BETWEEN h.시작일자 AND h.종료일자
SELECT c.고객번호, c.고객명, h.고객등급
FROM 고객 c, 고객등급이력 h
WHERE c.고객번호 = 123
AND h.고객번호 = c.고객번호
AND c.최종변경일자 BETWEEN h.시작일자 AND h.종료일자
- 선분이력 조인 Case 2: 직전선분 구하기
- ⭐⭐⭐
WHERE H.시작일자 < C.최종변경일자
AND H.종료일자 >= C.최종변경일자 - 1- H.시작일자 < C.최종변경일자
: 이력의 시작일자가 현재 변경일자보다 이전이어야 합니다. - H.종료일자 >= C.최종변경일자 -1
: 이력의 종료일자가 현재 변경일자 직전일자까지는 유효해야 합니다.
-1을 하는 이유: 연속된 이력 간 겹침 방지
- H.시작일자 < C.최종변경일자
- ⭐⭐⭐
SELECT c.고객번호, c.고객명, h.고객등급
FROM 고객 c, 고객등급이력 h
WHERE c.고객번호 = 123
AND h.고객번호 = c.고객번호
AND h.시작일자 < c.최종변경일자
AND h.종료일자 >= to_char(to_date(c.최종변경일자)-1), 'yyyymmdd');
✏️ 8. 점이력 조회
-- 상품변경이력_59 테이블
(#) 상품ID VARCHAR2(6)
(#) 변경일자 VARCHAR2(8)
(#) 순번 NUMBER
상태코드 VARCHAR2(3)
상품가격 NUMBER
-- 상품별 변경이력: 1000건
-- 일평균 변경이력: 10건- 점이력 조회 Case 1: 특정 상품의 최종 건 찾기
- ⭐⭐⭐
ORDER BY 변경일자 DESC, 순번 DESC
WHERE ROWNUM <= 1
- ⭐⭐⭐
SELECT *
FROM (SELECT *
FROM 상품변경이력_59
WHERE 상품ID = '000001'
ORDER BY 변경일자 DESC, 순번 DESC
)
WHERE ROWNUM <= 1; -- 해당하는 1건 읽고 STOP
- 점이력 조회 Case 2: 전체 상품의 최종 건 찾기
- ⭐⭐⭐
ROW_NUMBER() OVER(PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) R_NUM
WHERE R_NUM = 1;
*ROW_NUMBER(): 동일 순위 미인정 (DENSE_RANK: 동일 순위 1건으로 산정 / RANK: 순위)
- ⭐⭐⭐
SELECT *
FROM (SELECT 상품ID, 변경일자, 순번, 상태코드, 상품가격,
ROW_NUMBER() OVER (PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) R_NUM
FROM 상품변경이력_59
)
WHERE R_NUM = 1;
- 점이력 조회 Case 3: 전체 상품별, 상태코드별 최종 건 찾기
- ⭐⭐⭐
기존 방식:
ROW_NUMBER() OVER(PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) R_NUM
WHERE R_NUM = 1; - ⭐⭐⭐
KEEP 함수:
MAX(순번) KEEP (DENSE_RANK LAST ORDER BY 변경일자) 최종순번
MAX(상품가격) KEEP (DENSE_RANK LAST ORDER BY 변경일자, 순번) 최종상품가격
GROUP BY 상품ID, 상태코드
- ⭐⭐⭐
/*
출력 값:
상품ID, 상태코드,
최대상품가격, 최소상품가격, 평균상품가격, 최종변경일자,
최종순번 (최종변경일자의 최종순번),
최종상품가격 (최종변경일자의 최종순번의 상품가격)
*/
-- 기존 방식
SELECT 상품ID, 상태코드, 변경일자 AS 최종변경일자, 순번 AS 최종순번, 상품가격 AS 최종상품가격
FROM (SELECT 상품ID, 변경일자, 순번, 상태코드, 상품가격,
MAX(상품가격) OVER (PARTITION BY 상품ID, 상태코드) 최대상품가격,
MIN(상품가격) OVER (PARTITION BY 상품ID, 상태코드) 최소상품가격,
ROUND(AVG(상품가격) OVER (PARTITION BY 상품ID, 상태코드)) 평균상품가격,
ROW_NUMBER() OVER (PARTION BY 상품ID, 상태코드 ORDER BY 변경일자 DESC, 순번 DESC) RNUM
FROM 상품변경이력_59
)
WHERE RNUM = 1;
-- KEEP 함수 방식
SELECT 상품ID, 상태코드,
MAX(상품가격) 최대상품가격, MIN(상품가격) 최소상품가격,
ROUND(AVG(상품가격)) 평균상품가격,
MAX(변경일자) 최종변경일자,
MAX(순번) KEEP(DENSE_RANK LAST ORDER BY 변경일자) 최종순번,
MAX(상품가격) KEEP(DENSE_RANK LAST ORDER BY 변경일자, 순번) 최종상품가격,
FROM 상품변경이력_59
GOURP BY 상품ID, 상태코드;- 기존 방식 쿼리문 설명
- PARTION BY로 상품ID, 상태코드를 그룹화합니다.
- 각 그룹 내에서 MAX, MIN, AVG 계산합니다.
- ROW_NUMBER() OVER ~ ORDER BY 변경일자 DESC, 순번 DESC로 최신 데이터(=최종 값)을 선별합니다.
- KEEP 함수 쿼리문 설명
- KEEP 함수 문법
: 집계함수 KEEP (DENSE_RANK FIRST|LAST ORDER BY 정렬컬럼 [ASC|DESC])
- 집계함수: MAX, MIN, SUM, AVG, COUNT 등
- FIRST: 정렬 결과의 첫번째 값
- LAST: 정렬 결과의 마지막 값
- ORDER BY: 정렬 기준 지정
- KEEP 함수 문법
- 점이력 조회 Case 4: 원장과 이력테이블 조인하기
- 원장과 이력테이블 조인 - 1) 특정 데이터 조회하기
- ⭐⭐⭐ 외부 쿼리의 상품ID 참조하기 (상관 서브쿼리 기능)
- ⭐⭐⭐ Oracle 12c 이후 향상된 기능: LATERAL 키워드 (여기선 사용하지 않았음, 접은글 참고)
-- 상품 테이블
# 상품ID
* 상품명
* 구분코드
* 변경일자
* 상품가격
-- 상품변경이력 테이블
# 상품ID(FK)
# 변경일자
# 순번
* 상태코드
* 상품가격
-- 문제
상품 테이블의 구분코드가 '190'인 것 중
상품변경이력 테이블의 최종변경일자, 최종변경순번에 해당하는
상태코드를 조회하세요.
-- 정렬조건: 상품ID-- 오답: 전체 데이터 정렬 -> ROW_NUMBER로 순번 부여
SELECT P.상품ID, P.상품명, P.구분코드, H.변경일자, H.순번, H.상태코드
FROM 상품 P,
(SELECT 상품ID, 변경일자, 순번, 상태코드,
ROW_NUMBER() OVER(PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) RNUM
FROM 상품변경이력
) H
WHERE P.상품ID = H.상품ID
AND P.구분코드 = '190'
AND RNUM = 1;
-- 정답: 각 상품ID별 최신 데이터만 선택적으로 조회
SELECT P.상품ID, P.상품명, P.구분코드, H.변경일자, H.순번, H.상태코드
FROM 상품 P, 상품변경이력 H
WHERE P.상품ID = H.상품ID
AND P.구분코드 = '190'
AND (SELECT 변경일자, 순번
FROM (SELECT 변경일자, 순번
FROM 상품변경이력
WHERE 상품ID = P.상품ID -- ★ 여기에서 "외부 쿼리의 상품ID"를 참조합니다 ★
ORDER BY 변경일자 DESC, 순번 DESC)
WHERE ROWNUM = 1)
ORDER BY P.상품ID;- 특정 데이터 조회하기 - 오답 쿼리문 분석
- H.상품ID와 P.상품ID를 매칭하는 시점에 ROW_NUMBER()로 필터링된 데이터가 이미 축소된 상태입니다.
- RNUM = 1 조건이 서브쿼리에 적용되면서 H 테이블은 각 상품당 하나의 최종 레코드만 남게됩니다.
- 따라서 상품ID와 구분코드를 만족하는 데이터가 없을 경우, 전체 매칭이 실패할 수 있습니다.
- 특정 데이터 조회하기 - 정답 쿼리문 분석
- P.구분코드 = '190': 이 조건을 통해 관심 상품만 필터링합니다.
- 상품변경이력에서 최종변경일자, 최종변경순번 추출
- 서브쿼리를 사용하여 상품변경이력에서 상품ID를 기준으로 최종변경일자, 최종순변경순번을 찾습니다.
- 내부 서브쿼리 분석
- SELECT 변경일자, 순번
FROM 상품변경이력
WHERE 상품ID = P.상품ID
ORDER BY 변경일자 DESC, 순번 DESC - 데이터 필터링: 상품변경이력에서 현재 P.상품ID에 해당하는 데이터만 필터링합니다.
- 정렬 기준: 최신(변경일자 DESC, 순번 DESC) 데이터를 정렬 기준으로 설정합니다.
- SELECT 변경일자, 순번
- WHERE ROWNUM = 1
:서브쿼리에서 정렬된 데이터(현재 P.상품ID에 해당하는 데이터) 중 최상위 1개만 선택합니다. (최종 변경 데이터)
- 상품변경이력의 H.변경일자, H.순번 값이 상관 서브쿼리에서 반환된 값과 같을 때만 데이터를 반환합니다.
=> H 테이블에서 정확히 최종변경데이터를 찾는 데 사용됩니다.
-- LATERAL을 사용한 쿼리(Oracle 12c 이상부터 가능)
SELECT P.상품ID,
P.상품명,
P.구분코드,
L.변경일자,
L.순번,
L.상태코드
FROM 상품 P
CROSS APPLY (
SELECT H.변경일자, H.순번, H.상태코드
FROM 상품변경이력 H
WHERE H.상품ID = P.상품ID
ORDER BY H.변경일자 DESC, H.순번 DESC
FETCH FIRST 1 ROWS ONLY
) L
WHERE P.구분코드 = '190'
ORDER BY P.상품ID;
1. CROSS APPLY (LATERAL 키워드를 기반으로 동작)
- 테이블 P의 각 행마다 서브쿼리(L 부분)를 실행 → 서브쿼리의 결과를 메인 쿼리와 함께 반환합니다.
2. FETCH FIRST 1 ROWS ONLY
- ORDER BY: 최신 데이터(최종변경일자, 최종변경순번)를 찾기 위해 서브쿼리에서 정렬(ORDER BY H.변경일자~)
- FETCH FIRST 1 ROWS ONLY: 상위 한 개의 데이터만 가져옵니다. (기존의 ROWNUM = 1과 동일한 역할)
3. 기존 쿼리문(정답)과의 차이점
- 기존 쿼리문: 서브쿼리를 독립적으로 작성 → 외부 쿼리와 조건을 매칭
- LATERAL: 테이블 연결을 더 명시적으로 표현할 수 있습니다.
4. 기존 쿼리문(정답)과의 공통점
- WHERE P.구분코드 = '190': 메인 쿼리에서 처리합니다. (따라서 불필요한 데이터를 서브쿼리에서 계산X)
- 원장과 이력테이블 조인 - 2) 모든 데이터 조회하기
- ⭐⭐⭐ /*+ ORDERED FULL(P) FULL(H.상품변경이력) USE_HASH(H)*/
- USE_HASH가 적절한 경우
- 대량의 데이터를 처리할 때
- 조인 키에 인덱스가 없을 때
- 드라이빙 테이블이 작을 때 (메모리에 로드될 수 있을 정도로)
- 동등 조인(=) 조건일 때
- USE_HASH가 적절한 경우
- ⭐⭐⭐ /*+ ORDERED FULL(P) FULL(H.상품변경이력) USE_HASH(H)*/
-- 상품 테이블
# 상품ID
* 상품명
* 구분코드
* 변경일자
* 상품가격
-- 상품변경이력 테이블
# 상품ID(FK)
# 변경일자
# 순번
* 상태코드
* 상품가격
-- 문제
상품 테이블의 모든 데이터에서
상품변경이력 테이블의 최종변경일자, 최종변경순번에 해당하는
상태코드를 조회하세요.SELECT /*+ ORDERED FULL(P) FULL(H.상품변경이력) USE_HASH(H)*/
P.상품ID, P.상품명, P.구분코드, H.변경일자, H.순번, H.상태코드
FROM 상품 P,
(SELECT 상품ID, 변경일자, 순번, 상태코드,
ROW_NUMBER() OVER(PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) RNUM
FROM 상품변경이력
) H
WHERE P.상품ID = H.상품ID;
📒 정리하면
📌 누선최데복 점선징아 (징검다리 조인하기)
- 누적 매출 구하기: 기존의 자체 조인 방식, GROUP BY를 활용한 변경 방식, 윈도우 함수를 활용한 방식 중 윈도우 함수 방식이 가장 효율적입니다. (SUM OVER)
- 선분이력 끊기: GREATEST 시작일자, LEAST 종료일자, 시작일자 <= '20240131', 종료일자 >= '20240101'
- 최종 출력건에 대해서만 조인하기
- 일반적인 게시판 출력 방식: 쿼리블록이 항상 3개입니다. (1만건 읽어서 -> JOIN -> SORT 과정에서 STOPKEY 작동)
- 인덱스 추가로 튜닝하기: ROWID로 JOIN하면 인덱스 없이도 특정 행을 즉시 찾을 수 있습니다. (41건 읽으면서 STOPKEY 작동 -> JOIN)
- 데이터 복제를 통한 소계 구하기
- 월별 집계만 수행
- 전통적인 방식: DECODE (NO, 1, TO_CHAR(EMPNO), 2, '부서계') 사번
- ROLLUP 함수:
CASE WHEN GROUPING (EMPNO) = 1 AND GROUPING (DEPTNO) = 1 THEN '총계'
CASE WHEN GROUPGIN (EMPNO) = 1 THEN '부서계'
GROUP BY ROLLUP(DEPTNO, EMPNO) - 일별, 월별 집계 동시 수행
- UNION ALL 사용하는 방식: SELECT문 2개, UNION ALL
- GROUPING SET 함수:
GROUP BY GROUPING SET(
(TO_CHAR(ORDER_DT, 'yyyymmdd'), CUST_NO), --일별
(TO_CHAR(ORDER_DT, 'yyyymm'), CUST_NO)) -- 월별
- 월별 집계만 수행
- 점이력 조회하기
- 특정상품의 최종건:
ORDER BY 변경일자 DESC, 순번 DESC
WHERE ROWNUM <= 1 - 전체 상품의 최종건:
ROW_NUMBER() OVER (PARTITION BY 상품ID ORDER BY 변경일자 DESC, 순번 DESC) R_NUM
WHERE R_NUM = 1 - 전체 상품별, 상태코드별 최종:
MAX(순번) KEEP (DENSE_RANK LAST ORDER BY 변경일자) 최종순번
MAS(상품가격) KEEP (DENSE_RANK LAST ORDER BY 변경일자, 순번) 최종상품가격
GORUP BY 상품ID, 상품코드 - 원장과 이력테이블 조인:
[특정 데이터 조회] 외부 쿼리의 상품ID 참조하기
(상관 서브쿼리 기능: WHERE 상품ID = P.상품ID / Oracle 12c 이후: LATERAL 키워드)
[모든 데이터 조회] /*ORDER FULL(P) FULL(H.상품변경이력) USE_HASH(H)*/
- 특정상품의 최종건:
- 선분이력 조인하기
- 최종이력 구하기: 상수 BETWEEN 시작일자 AND 종료일자
- 직전선분 구하기:
WHERE H.시작일자 < C.최종변경일자
AND H.종료일자 >= C.최종변경일자 -1
- 아크 관계의 조인하기(상호배타적 관계): 외래키 분리/통합 방법이 있습니다.
- 외래키 분리:
AND B.온라인권번호 (+) = A.온라인권번호 -- RIGHT OUTER JOIN
AND C.실권번호 (+) = A.실권번호 - 외래키 통합:
[인덱스: 결제일자 + 상품권구분]
WHERE A.결제일자 BETWEEN :DATE1 AND :DATE2
AND B.온라인권번호 (+) = DECODE(A.상품권구분, '1', A.상품권번호)
AND C.실권번호 (+) = DECODE(A.상품권구분, '2', A.상품권번호)
[인덱스: 상품권구분 + 결제일자]
SELECT ... WHERE A.상품권구분 = '1' ....
UNION ALL
SELECT ... WHERE A.상품권구분 = '2' ...
- 외래키 분리: