🖥️ 들어가며
📌조인 순서의 중요성
: 조인 종류에 따라 어떤 순서로 드라이빙 테이블을 결정할지 그 기준이 상이합니다.
✏️ 1. Nested Loop 조인
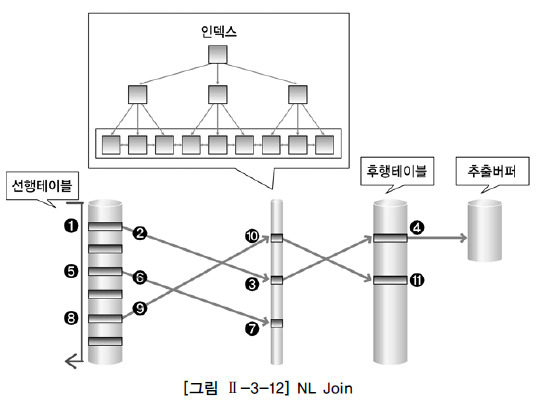
- 기본 매커니즘
- for문(Java의 중첩 루프문)과 동일한 원리입니다.
- 반복문의 외부에 있는 테이블 = 선행 테이블 = 외부 테이블 = Outer Table
- 반복문의 내부에 있는 테이블 = 후행 테이블 = 내부 테이블 = Inner Table
- 선행 테이블 조건에 만족하는 첫번째 행 추출 → 후행 테이블 읽으면서 조인 → 선행 테이블 조건을 만족하는 모든 행의 수만큼 반복수행
=> 선행 테이블 조건에 만족하는 행의 수가 많으면 그만큼 후행 테이블 조인작업을 반복수행하게 됩니다.
- 특징
- Look up 테이블의 join 컬럼에 index가 있는 것이 유리합니다.
(전체 테이블 스캔을 피할 수 있어 → 빠른 데이터 검색 가능, 조인 성능 향상시킬 수 있음) - R.A 위주의 조인 방식이므로 → 대량 데이터 조인 시 대체로 비효율적입니다.
(각 외부 테이블 행마다 내부 테이블 반복적으로 액세스 → 대용량 처리에 적합하지 않을 수 있음) - 조인을 한 레코드씩 순차적으로 진행합니다. (한 번에 한 레코드씩 처리 → 전체 데이터셋 메모리에 로드 X, 작업 수행 O)
→ 대용량 집합이라도 극적인 응답속도 낼 수 있고, 먼저 액세스되는 테이블의 처리 범위에 의해 전체 일량이 결정됩니다.
=> 선행 테이블은 처리 범위가 좁은 것의 조건으로 선택하는 것이 유리합니다. - 다른 조인 방식보다 인덱스 구성 전략이 매우 중요합니다.
- 소량의 데이터 처리하거나 부분범위 처리 가능, 성공하면 바로 사용자에게 결과를 보여주므로 OLTP 환경에 적합합니다.
- 조인 조건이 등가 조건이 아닌 경우에도 사용할 수 있습니다.
- Look up 테이블의 join 컬럼에 index가 있는 것이 유리합니다.
✏️ 2. Sort merge 조인

- 기본 매커니즘
- 조인 컬럼을 기준으로 데이터를 정렬(소트) → 조인을 수행합니다.
- 소트 단계: 양쪽 집합을 조인 컬럼 기준으로 정렬합니다.
- 머지 단계: 정렬된 양쪽 집합을 merge 합니다. (본 작업은 PGA에서 수행합니다.)
- 조인을 위해 실시간으로 인덱스를 생성하는 것과 같은 효과입니다. (조인 컬럼에 인덱스 유무와 상관 없음)
- 선행 테이블에서 주어진 조건에 만족하는 행 찾음 → 선행 테이블의 조인 컬럼 기준으로 정렬 작업 수행(조건을 만족하는 모든 행 반복 수행) → 후행 테이블에서 주어진 조건을 만족하는 행 찾음 → 후행 테이블의 조인 컬럼을 기준으로 정렬 작업 수행(조건을 만족하는 모든 행 반복 수행) → 정렬된 결과를 이용해 조인 수행
=> 조인 성공 시 추출 버퍼에 넣습니다.
- 조인 컬럼을 기준으로 데이터를 정렬(소트) → 조인을 수행합니다.
- 특징
- PGA 영역에서 처리 → 빠른 속도 (래치 경합 없이 빠르게 접근 가능)
- 소트 부하만 감수한다면 버퍼 캐시에서 조인하는 NL 조인보다 유리할 수 있습니다.
- 주로 스캔 방식으로 데이터를 읽습니다.
- R.A로 부담이 되는 넓은 범위의 데이터를 처리할 때 유용합니다.
- 부분범위 처리가 가능합니다. (정렬된 데이터를 순차적으로 처리하므로 중간에 처리를 멈출 수 있음)
- Array Size에 의해서 부분범위 처리 가능하며 (데이터 양 조절 가능), 인덱스 구성에 따라 sort 연산을 생략할 수 있습니다.
- 테이블별 검색 조건에 의해 전체 일량이 좌우됩니다.
- 정렬할 데이터가 많아 메모리에 모든 정렬작업을 수행하기 어려운 경우, 임시영역을 사용해 성능이 떨어질 수 있습니다. (대용량 데이터 정렬 시 디스크 I/O 발생하여 성능 저하 될 수 있음)
- 활용 상황
- 선행 테이블에 소트 연산을 대체할 인덱스가 있을 때
- 조인할 선행 집합이 이미 정렬되어 있을 때 (PGA에서 추가적인 정렬 작업 없이 SGA에서 직접 데이터를 읽어 조인할 수 있음)
- 조인 조건식이 등치 조건이 아닐 때 (Hash Join과는 달리 동등 조인, 비동등 조인 모두 조인 작업이 가능)
✏️ 3. Hash 조인

- 기본 매커니즘
- 조인 컬럼을 기준으로 해쉬함수를 수행해, 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지 비교하면서 조인을 수행합니다. (해슁기법으로 조인 수행)
- 선행 테이블 = Build Input
(두 개의 테이블 중 작은 집합을 읽어 Hash Area에 적재. Build Input이 Hash Area 크기 안에 들어가는 것이 성능 성패 좌우) - 후행 테이블 = Prove Input
- NL Join의 R.A와 Sort Merge Join의 문제점인 정렬 작업의 부담을 해결하기 위한 대안으로 등장했습니다.
(따라서 R.A, Sort 부하 없음) - 선행 테이블에서 주어진 조건을 만족하는 행을 찾음 → 선행 테이블의 조인 컬럼을 기준으로 해쉬 함수 적용, 해쉬 테이블 생성(선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행) → 후행 테이블에서 주어진 조건을 만족하는 행을 찾음 → 후행 테이블의 조인 컬럼을 기준으로 해쉬 함수 적용, 해쉬 테이블 생성(후행 테이블의 조건을 만족하는 )
- 사용 기준
- 한쪽 테이블(Build Input)이 Hash Area에 담길 정도로 충분히 작아야 합니다.
- Build Input 해쉬 키 컬럼에 중복 값이 거의 없어야 합니다.
- 1:M 관계에서 1쪽이 Build Input으로 올라가야 합니다.
- 특징
- 조인 컬럼의 인덱스가 존재하지 않는 경우에도 사용할 수 있습니다. (해쉬 테이블을 사용하므로 인덱스에 의존 X)
- 해쉬 함수를 이용하여 조인 수행하므로 → 등치 조건만 사용할 수 있습니다. (해쉬 함수 기본 특성: 동일한 입력엔 항상 같은 값으로 해슁되는 것이 보장)
- 작업 수행을 위해선 메모리에 해쉬 테이블을 생성합니다.
- 메모리에 적재할 수 있는 영역 크기보다 커지면 임시 영역(디스크)에 해쉬 테이블을 저장합니다.
- 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋습니다.
- 래치 획득과정이 없는 PGA에서 처리 → 빠른 탐색 과정
- 활용 상황
- 조인 컬럼에 적당한 인덱스가 없어 NL 조인이 비효율적일 때
- 조인 컬럼에 인덱스가 있더라도 NL 조인 드라이빙 집합에서 Inner쪽 집합으로의 조인 액세스양이 많아 R.A 부하가 심할 때
- Sort merge 조인하기에 두 테이블이 너무 커 Sort 부하가 심할 때
- 수행빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 조인할 때
- 배치 작업
- 수행 빈도가 높고 OLTP 환경하의 SQL 성능향상을 위해선 사용해서는 안 됩니다.
(PGA에 테이블을 다 올림 + Hash Function 수행
=> CPU, 메모리 사용률 크게 증가하여 전반적으로 자원 사용률을 높임)
- ⭐⭐⭐Hash 조인 실행계획
- 등호형
- 테이블을 순차적으로 조인합니다.
- 각 단계의 결과를 다음 단계의 Hash Area에 적재합니다.
- 메모리 사용량이 상대적으로 적습니다.
- 예시
- 1. T_APRP 테이블을 Hash Area 적재 후 T_CARD를 읽어 탐색
- 2. 1의 결과를 다시 Hash Area 적재 후 T_MERCH(Probe) 읽어 탐색
- 3. 2의 결과를 다시 Hash Area 적재 후 T_PROD(Probe) 읽어 탐색
- 4. 3의 결과를 다시 Hash Area 적재 후 T_CUST(Probe) 읽어 탐색
- /*+ ORDERED USE_HASH(E) USE_HASH(X) NO_SWAP_JOIN_INPUTS(X)*/
- ORDERED: FROM 절에 나온 순서대로 조인 수행
- USE_HASH(E), USE_HASH(X): E, X 테이블에 대해 해쉬 조인
- NO_SWAP_JOIN_INPUTS(X): X 테이블을 Probe 테이블로 사용
- 계단형
- 여러 테이블을 동시에 Hash Area에 적재합니다.
- 병렬 처리 유리, 메모리 사용량이 더 많습니다.
- 예시
- 1. T_CUST, T_PROD, T_MERCH, T_APPR을 각 Hash Area에 적재
- 2. T_CARD를 읽어 탐색
- 3. 2의 결과로(Probe) T_MERCH 탐색
- 4. 3의 결과로(Probe) T_PROD 탐색
- /*+ ORDERED USE_HASH(E) USE_HASH(X) SWAP_JOIN_INPUTS(X)*/
- SWAP_JOIN_INPUTS(X): X 테이블을 Build 테이블로 사용
- 아래 실행계획은 ↓←를 위배합니다.
- 등호형
SELECT /*+ ORDERED USE_HASH(E) USE_HASH(X) SWAP_JOIN_INPUTS(X)*/
D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME, X.EMPNO, X.ENAME
FROM DEPT D, EMP E, T_EMP X
WHERE D.DEPTNO = E.DEPTNO
AND E.EMPNO = X.EMPNO;
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 432 | 9 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 12 | 432 | 9 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | T_EMP| 12 | 120 | 3 (0)| 00:00:01 |
| 3 | HASH JOIN | | 12 | 312 | 6 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| DEPT | 4 | 52 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL| EMP | 12 | 156 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------- 실행계획: 4 → 5 → 3 → 2 → 1 → 0
- 원래대로라면 2부터 시작하는 게 맞지만, Hash 조인이 수행되려면
- 먼저 두 테이블의 데이터가 준비되어 있어야 합니다.
- 그래야 이 데이터들을 사용해서 조인을 수행할 수 있습니다. - 따라서 3번의 Hash Join을 수행하기 위해서는
- DEPT 테이블 전체를 읽고 (4 수행)
- EMP 테이블 전체를 읽은 후 (5 수행) 실제 조인 작업이 가능합니다. - 즉, Hash 조인에 필요한 데이터를 먼저 준비하기 위해 4, 5번 작업이 선행되어야 하는 것입니다.
- 원래대로라면 2부터 시작하는 게 맞지만, Hash 조인이 수행되려면
👉🏻 조인에 힌트를 주는 방법
1. 조인 순서 지정 힌트
- ORDERED: From 절에 나열된 테이블 순서대로 조인 수행
- LEADING: 지정된 순서대로 조인 수행
2. 조인 방법 지정 힌트
- USE_NL: Nested Loop 조인 방식 사용 지시
- USE_MERGE: Sort Merge 조인 방식 사용 지시
- USE_HASH: Hash 조인 방식 사용 지시
✏️ 4. 조인 순서의 중요성
- NL 조인
- 적은 쪽(조건에 맞는 레코드 수) → 큰 쪽으로
- Sort Merge 조인
- Disk sort가 필요한 경우, 큰 테이블 드라이빙이 유리합니다. (큰 테이블을 한 번에 정렬 → Disk I/O 횟수 감소 유도)
- PGA Sort Area 안에 담길 경우, 적은 테이블 드라이빙이 유리합니다. (Join 횟수 감소 유도)
- Hash 조인
- Hash Area에 충분히 담길 정도로 적은 테이블이 드라이빙(Build Input) 되어야 합니다.
📒 정리하면
- Nested Loop 조인: 선행 테이블 중 조건에 만족하는 행의 수만큼 후행 테이블 조인작업 반복 수행, 조인 컬럼에 인덱스가 포함되는 것이 유리, 한 레코드씩 순차적으로 조인 진행, OLTP 환경에 적합합니다.
- Sort Merge 조인: 양쪽 테이블을 정렬 후 병합, 실시간으로 인덱스를 생성하는 것과 같은 효과, 대용량 데이터 처리에 유용, Hash 조인과 달리 비동등 조인 가능합니다.
- Hash 조인: NL 조인의 R.A, Sort Merge 조인의 Sort 부하가 없음, 조인 컬럼을 기준으로 해쉬 함수 적용해 해쉬 테이블 생성, 대용량 데이터 처리에 유용, 동가 조인만 가능합니다.
- Hash 조인 실행계획: 등호형(테이블을 순차적으로 조인, NO_SWAP_JOIN_INPUT), 계단형(여러 테이블을 동시에 Hash Area에 적재, SWAP_JOIN_INPUT)
- 조인 순서 최적화: NL 조인(적은 쪽 → 큰 쪽), Sort Merge Join(Disk sort가 필요하다면 큰 테이블부터 / PGA Sort Area 안에 담긴다면 적은 테이블부터), Hash 조인(Hash Area에 충분히 담길 적은 테이블부터 드라이빙)
반응형



