🖥️ 들어가며
📌 인덱스 종류
- B-Tree 인덱스, 비트맵 인덱스, 함수기반 인덱스, 리버스 인덱스, Clustered Index, IOT
📌 결합 인덱스 설계시 고려사항
- 조건절에 자주 사용되는 컬럼, 등치 조건으로 사용되는지, 카디널리티가 좋은지, 소트 연산을 대체할 수 있는지
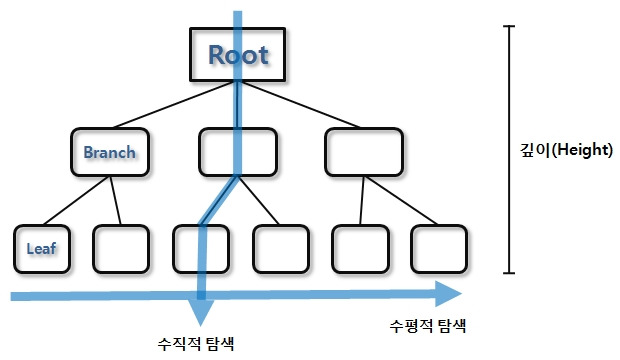
✏️ 1. B-Tree 인덱스
- Unbalanced Index
- B-Tree에서 B는 Balanced이므로, Unbalanced Index는 없습니다.
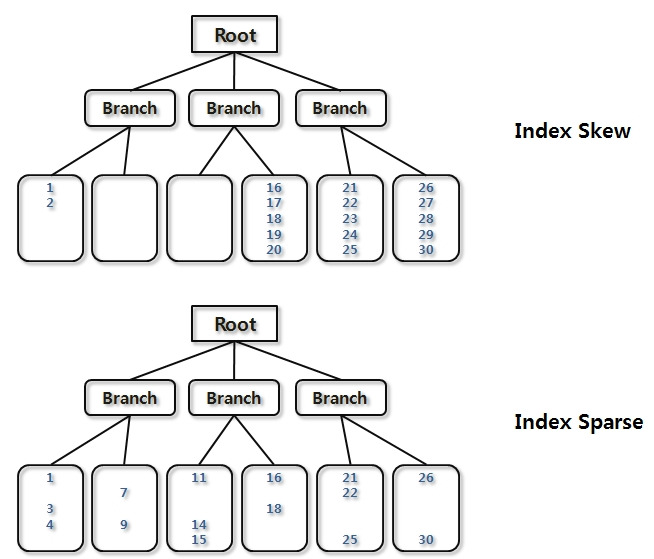
- Index Skew 현상
- Index 정렬 순으로 특정 방향의 데이터가 대량으로 Delete되어 Leaf Block이 빈 상태를 말합니다.
- Leaf Block은 완전히 비어있을 때만 Freelist(Free Block)로 반환됩니다.
(부분적으로 비어있는 블록은 인덱스 구조에 남아있습니다.) - 상위 Branch 범위에 해당하는 값 입력 시, 다른 노드에 인덱스 분할이 발생하면 재사용 가능합니다.
(재사용 전까지 Scan 효율 매우 낮음) - *Memory buffer 상태
- Dirty Buffer: 데이터가 변경되었지만 아직 디스크에 기록되지 않은 버퍼, 메모리에서 에이징 아웃되지 않습니다. (디스크에 쓰여질 때까지 메모리에 유지됨)
- Pinned Buffer: 현재 사용자 세션에 의해 사용 중인 버퍼입니다. 다른 프로세스가 이 버퍼를 수정하거나 제거할 수 없도록 Buffer Pinning된 상태로, 해당 세션이 작업을 완료할 때까지 메모리에 유지됩니다.
- Free Buffer: 사용 가능한 상태의 버퍼입니다. (아직 한 번도 사용하지 않았거나 / 이전에 사용되었지만 현재 사용 가능한 상태가 되었거나)
- *Disk Block 상태
- Free Block: 사용 가능한 빈 블록
- Used Block: 데이터가 저장된 블록
- Index Sparse
- 대량의 데이터 Delete 작업 후 발생, 전반적으로 Leaf Block의 인덱스 밀도가 저하된 상태입니다.
- Skew 현상과 같이 완전히 빈 블록은 재사용되지만,
(Skew 현상과 달리) 동 현상은 완전한 Empty Block이 거의 없어 데이터가 채워질 때까지 인덱스 스캔 비효율이 발생합니다.
(부분적으로 비어있는 블록은 인덱스 구조에 남아있고, 새로운 데이터가 삽입될 때 재사용될 수 있습니다.) - 레코드 건수가 일정해도 Index Size(인덱스 공간 사용량)만 증가합니다.
- Index 재생성
- 인덱스 생성 → 데이터 정렬 → 입력
정렬하는 과정에서 오버헤드가 발생할 수 있습니다.
따라서 인덱스 재생성은 작업의 부하를 일으킬 수 있기에, 확실한 효과가 예상될 때만 시행하는 것이 바람직합니다. - 인덱스 재생성이 필요한 시점
- 인덱스가 빈번하게 분할될 때
(많은 데이터 삽입/삭제, 불규칙한 데이터 업데이트, 인덱스 크기 증가 등 때문) - 자주 사용되는 인덱스 스캔의 효율을 높이고자 할 때
- NL Join에서 반복 액세스되는 인덱스의 높이가 증가했을 때
(인덱스가 깊어짐 = Depth가 커짐 → 탐색에 걸리는 시간이 길어짐, 인덱스 구조가 조정되어 페이지 분할이 빈번히 일어나기 때문) - 대량의 Delete 작업 후 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
(삭제된 공간이 인덱스에 비효율적으로 남아있을 수 있음 → 빈 공간 정리, 효율적인 구조로 리빌드) - 총 레코드 수가 일정한데도 Index Size가 계속 커질 때
(위 경우는 인덱스에 불필요한 데이터 추가 혹은 단편화*가 심각해졌을 가능성 높음)
*인덱스 단편화: 효율적으로 데이터가 정렬되지 않거나 불규칙하게 분포 → 페이지에 비어있는 공간이나 작은 조각들이 남아 성능 저하
- 인덱스가 빈번하게 분할될 때
- 인덱스 생성 → 데이터 정렬 → 입력
✏️ 2. 비트맵 인덱스
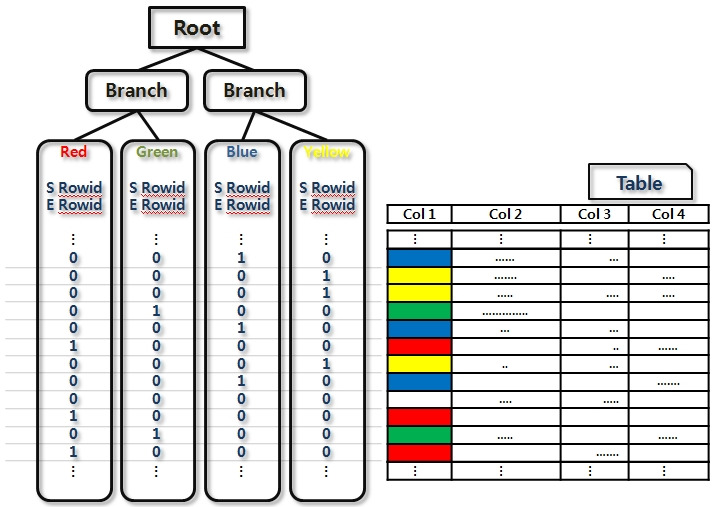
- 특징
- Null 저장합니다.
- 부정형 조건 사용 시에도 Scan 가능합니다.
- 다중 인덱스 사용: 여러 Bitmap Index를 동시에 사용하기 쉽습니다. (Bitmap Index Merge)
- 활용 방안
- Distinct value의 개수가 적은 컬럼일 때 저장 효율이 높습니다.
- 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량 테이블에 유용합니다.
=> 여러 비트맵 인덱스를 동시 활용 시 대용량 데이터 검색 성능을 향상 시킵니다. - DML 작업 시 동일한 Bitmap 범위의 모든 레코드에 Lock을 겁니다.
=> OLTP 환경에서는 절대 XXXXX - 다양한 분석관점(Dimension)을 가진 팩트성 테이블에 주로 사용, 비정형 쿼리(ad-hoc query)가 많을 때 적합하므로
=> 일반적으로 DW DB 환경에 적합합니다.
- B-Tree 인덱스 한계 vs. 비트맵 인덱스의 장점
- B-Tree 인덱스
- IN 조건: 각 값에 대해 별도의 수직적 탐색을 수행합니다.
- OR 조건: 각 조건에 대해 별도의 인덱스 스캔을 수행한 결과를 UNION ALL 합니다. - 비트맵 인덱스
- IN, OR 조건: 비트 OR 연산으로 빠르게 결합합니다.
*비트 OR 연산: 두 개 비트 중 하나라도 1이면 1 / 비트 AND 연산 두 개 비트가 모두 1일 때만 1
- B-Tree 인덱스
✏️ 3. 함수기반 인덱스(FB Index, Function Based Index)
- 구조
- 컬럼 값에 가공함수를 적용한 값으로 Index를 생성합니다.
- 활용 방안
- NULL 처리: 아래 쿼리문과 같이 주문 수량이 Null인 레코드에 0으로 채워진 인덱스를 생성합니다.
- 대소문자 구분 없는 검색: 대소문자를 구분해서 입력 받은 데이터를 대소문자 구분없이 조회할 때 사용합니다.
- DML로 인한 인덱스 갱신 시 함수까지 적용해야 하기에 부하가 발생할 수 있습니다.
사용된 함수가 User-Defined 함수일 경우 부하가 심합니다.
=> 컬럼을 가공한 값을 이용해 데이터를 검색해야만 할 때, 꼭 필요한 경우에만 활용합니다.
SELECT * FROM 주문
WHERE NVL(주문수량, 0) < 100;
-- 함수기반 인덱스
CREATE INDEX emp_x01 ON 주문(NVL(주문수량, 0));
✏️ 4. 리버스 인덱스(Reverse Key Index)
- 구조
- B-Tree와 유사하나 Leaf의 Key 값이 글자 역순입니다.
- reverse(column) 함수를 적용하여 인덱스를 생성한 것과 같습니다.
- 활용 방안
- Right Growing 현상으로 Insert 시, 동일한 인덱스 블록에 대한 경합이 심할 때 사용하면 효율적입니다.
(일련번호, 주문일시 등의 컬럼으로 인덱스를 만들 때)- Insert가 심할 때 발생하는 인덱스 블록 경합을 감소시켜 초당 트랜잭션 처리량을 향상 시킵니다.
- 입력된 데이터를 거꾸로 변환하여 저장하기 때문에 데이터가 고르게 분포합니다.
- 등치(=) 조건 입력시에만 사용할 수 있습니다.
- Right Growing 현상으로 Insert 시, 동일한 인덱스 블록에 대한 경합이 심할 때 사용하면 효율적입니다.

✏️ 5. Clustered Index, IOT(Index Organized Table)
👉🏻 [SQL튜닝/인덱스와 조인] IOT와 Clustered Index (인덱스 구조로 저장, 읽기 전용, PK 기반 범위 검색)
[SQL튜닝/인덱스와 조인] IOT와 Clustered Index (인덱스 구조로 저장, 읽기 전용, PK 기반 범위 검색)
🖥️ 들어가며📌 Clustered Index: 테이블의 물리적 순서를 결정하고, 테이블당 하나만 생성할 수 있습니다.논리적으로 사번 / 이름 + 입사일자 / 연봉에 대한 각 Clustered Index를 만들 순 없습니다. [
techdotori.tistory.com
✏️ 6. 결합 인덱스 설계
- 결합 인덱스 구성을 위한 기본 조건
- 조건절에 자주 사용되는 컬럼
- 등치(=, IN) 조건으로 사용되는지 (드라이빙)
- 카디널리티가 좋은지 (분포도가 낮을수록 = 고유한 값의 비율이 높을수록 = 변별력이 있음)
- 소트 연산을 대체할 수 있는지
SELECT *
FROM T
WHERE C1 = 'A'
ORDER BY C3
-- 인덱스: C1 -> 정렬 연산 필요
-- 인덱스: C1 + C3 -> 정렬 연산 X
SELECT *
FROM T
WHERE C1 = 'A'
AND C2 BETWEEN 1 AND 10
ORDER BY C3
-- 인덱스: C1 + C3 + C2 -> 정렬 연산 X
- 추가 고려사항
- 쿼리 수행 빈도수가 높은 것
- 업무상 중요도가 높은 것
- C.F
- 데이터량
- DML 부하(기존 인덱스 개수, 초당 DML 발생량, 자주 갱신되는 컬럼 포함 여부 등)
- 저장 공간
- 인덱스 관리 비용 등
📒정리하면
- B-Tree 인덱스: 균형 잡힌 구조를 유지, Index Skew와 Sparse 현상이 성능 저하의 원인이 될 수 있습니다.
(인덱스 재생성이 필요한 시점: 인덱스가 빈번하게 분할될 때, 자주 사용되는 인덱스 스캔 효율 높이고 싶을 때, NL Join에서 반복 액세스되는 인덱스 높이가 증가했을 때, 대량 Delete 작업 후 레코드가 입력되기까지 오랜 기간이 소요될 때, 총 레코드 수가 일정한데도 Index Size가 계속 커질 때) - 비트맵 인덱스: 고유 값이 적은 컬럼에서 효과적, 대용량 데이터를 다차원으로 분석할 때, 비정형 쿼리에 적합합니다. (DW DB 적합, OLTP XXXXX)
- 함수기반 인덱스: 컬럼 값에 함수를 적용한 결과로 인덱스를 생성, 특정 검색 조건에 유용합니다. (NULL 처리, 대소문자 구분 없는 검색)
- 리버스 인덱스: 키 값을 역순으로 저장, Right Growing 현상으로 인한 인덱스 블록 경합을 감소시킵니다.
- 결합 인덱스 설계 시 고려사항: 조건절 사용 빈도, 등치 조건 여부, 카디널리티, 정렬 연산 대체 가능성 등을 고려해야 합니다.
반응형



